Критерий Манна-Уитни представляет непараметрическую альтернативу t-критерия для независимых выборок. Преимущество его состоит в том, что мы отказываемся от предположения нормальности распределения и одинаковых дисперсий. Необходимо, чтобы данные были измерены как минимум в порядковой шкале.
STATISTICA предполагает, что данные расположены тем же образом, что в и t-критерии для независимых выборок. Файл должен содержать кодовую (независимую) переменную, имеющую, по крайней мере, два разных кода для однозначной идентификации принадлежности каждого наблюдения к определенной группе.
Предположения и интерпретация. Критерий Манна-Уитни предполагает, что рассматриваемые переменные измерены, по крайней мере, в порядковой шкале (ранжированы). Интерпретация теста по существу похожа на интерпретацию результатов t-критерия для независимых выборок, за исключением того, что U критерий вычисляется, как сумма индикаторов попарного сравнения элементов первой выборки с элементами второй выборки. U критерий — наиболее мощная (чувствительная) непараметрическая альтернатива t-критерия для независимых выборок; фактически, в некоторых случаях он имеет даже большую мощность, чем t-критерий.
Если объем выборки больше 20, то распределение выборки для U статистики быстро сходится к нормальному распределению (см. Siegel, 1956). Поэтому вместе с U статистикой будут показаны z значение (для нормального распределения и соответствующее p-значение.
Точные вероятности для малых выборок. Для выборок малого объема STATISTICA вычислит точную вероятность, связанную с соответствующей U статистикой. Эта вероятность основана на подсчете всех возможных значений U при заданном количестве наблюдений в двух выборках (см. Dinneen & Blakesley, 1973). Программа сообщит (в последнем столбце таблицы результатов) значение 2 * p, где p равно 1 минус кумулятивная (односторонняя) вероятность соответствующей U статистики. Заметим, что это обычно не приводит к большой недооценке статистической значимости соответствующих эффектов (см. Siegel, 1956).
Статистика критерия выглядит следующим образом.
![]()
где W — статистика Вилкоксона, предназначенная для проверки этой же гипотезы
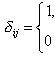
1 если ![]()
0 в противном случае
Таким образом, статистика U считает общее число тех случаев, в которых элементы второй выборки превосходят элементы первой выборки. Если гипотеза верна, то
Критерий Манна-Уитни предполагает, что рассматриваемые переменные измерены, по крайней мере, в порядковой шкале (ранжированы). Интерпретация теста по существу похожа на интерпретацию результатов t-критерия для независимых выборок, за исключением того, что U критерий вычисляется, как сумма индикаторов попарного сравнения элементов первой выборки с элементами второй выборки. U критерий — наиболее мощная (чувствительная) непараметрическая альтернатива t-критерия для независимых выборок; фактически, в некоторых случаях он имеет даже большую мощность, чем t-критерий.
Если объем выборки больше 20, то распределение выборки для U статистики быстро сходится к нормальному распределению. Поэтому, вместе с U статистикой, будут показано z значение (для нормального распределения) и соответствующее p-значение.
Подробные инструкции по поводу того, как использовать критерий, вы можете найти дальше в части, касающейся примера применения.
Пример
Проверим гипотезу о принадлежности сравниваемых независимых выборок к одной и той же генеральной совокупности с помощью непараметрического U-критерия Манна-Уитни. Сравним результаты, полученные в примере Основные статистики и t-критерий Стьюдента для 2-го и 3-го столбцов таблицы по критерию Стьюдента, с результатами непараметрического сравнения.
Для расчета U-критерия Уилкоксона расположим варианты сравниваемых выборок в порядке возрастания в один обобщенный ряд и присвоим вариантам обобщенного ряда ранги от 1 до n1 + n2. Первая строка представляет собой варианты первой выборки, вторая — второй выборки, третья — соответствующие ранги в обобщенном ряду:
| 6 | 7 | 7 | 8 | 8 | 9 | 9 | 9 | 10 | 11 | ||||||||||
| 8 | 9 | 9 | 11 | 11 | 12 | 12 | 12 | 13 | 13 | ||||||||||
| 1 | 2,5 | 2,5 | 5 | 5 | 5 | 9 | 9 | 9 | 9 | 9 | 12 | 14 | 14 | 14 | 17 | 17 | 17 | 19,5 | 19,5 |
Надо обратить внимание, что если имеются одинаковые варианты, им присваивается средний ранг, однако значение последнего ранга должно быть равно n1 + n2 (в нашем случае 20). Это правило используют для проверки правильности ранжирования.
Отдельно для каждой выборки рассчитываем суммы рангов их вариант R1 и R2. В нашем случае:
R1 = 1 + 2,5 + 2,5 + 5 + 5 + 9 + 9 + 9 + 12 + 14 = 69
R2 = 5 + 9 + 9 + 14 + 14 + 17 + 17 +17 + 19,5 + 19,5 = 141
Для проверки правильности вычислений можно воспользоваться другим правилом: R1 + R2 = 0,5 * (n1 + n2) * (n1 + n2 + 1). В нашем случае R1 + R2 = 210.
Статистика U1 = 69 — 10*11/2 = 14; U2 = 141 — 10*11/2 = 86.
Для проверки одностороннего критерия выбираем минимальную статистику U1 = 14 и сравниваем ее с критическим значением для n1 = n2 = 10 и уровня значимости 1%, равным 19.
Так как вычисленное значение критерия меньше табличного, нулевая гипотеза отвергается на выбранном уровне значимости, и различия между выборками признаются статистически значимыми. Таким образом, вывод о существовании различий, сделанный с помощью параметрического критерия Cтьюдента, подтверждается с помощью данного непараметрического метода.